| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- H는 통계를 모른다.
- 제시 리버모어
- 김프
- 퀀트 트레이딩
- 파이어족 저축
- 이클립스
- 니콜라스 다바스
- 에드워드 소프
- 신의 시간술
- 마크미너비니
- 자산배분
- eclipse
- 통계적 유의성
- python
- 파이어족 포트폴리오
- 2%룰
- AWS
- tensorflow
- 데이비드 라이언
- 데이빗 라이언
- 아웃풋 트레이닝
- 파이어족 자산증식
- 파이어족 자산
- 퀀터스 하지 마세요
- 추세추종 2%룰
- GIT
- 마크 미너비니
- 연금저축계좌
- 파이어족
- mark minervini
- Today
- Total
머신러닝과 기술적 분석
mAP (mean average precision) 의 개념 본문
Computer Vision 쪽에 Object Detection 알고리즘 논문을 보면 성능평가지표로 mAP (mean Average Precision) 이라는 것을 이용한다.
mAP 란 무엇인지 알아보고 python 으로 구현하는 방법을 정리하자.
Contents
- mAP (mean Average Precision)
- python code
1. mAP (mean Average Precision)
먼저 용어해석을 통해 mAP 가 대략적인 의미를 알아보자.
Precision : 분류기의 성능평가지표로 사용하는 Precision-Recall 에서의 Precision과 같은 의미이다. 인식기 (object-detector) 가 검출한 정보들 중에서 Ground-Truth 와 일치하는 비율을 의미한다.
AP (Average Precision) : Recall value [0.0, 0.1, …, 1.0] 값들에 대응하는 Precision 값들의 Average 이다.
mAP (mean Average Precision) : 1개의 object당 1개의 AP 값을 구하고, 여러 object-detector 에 대해서 mean 값을 구한 것이 mAP 이다.
* Note: mAP 를 이해하기 위해서는 Precision-Recall 값에대한 이해가 필요하다. Precision / Recall 를 참고하자. *
즉 mAP란 mutiple object detection 알고리즘에 대한 성능을 1개의 scalar value로 표현한 것이다.
2. mAP 를 구하는 방법
The PASCAL Visual Object Classes (VOC) Challenge (1) 수식에 보면 object detection 의 성능평가 지표로 mAP 를 어떻게 구하는 지가 나와있다. 이를 토대로 구하는 순서를 정리해보자.
2.1 recall-precision 그래프를 그린다.
웹상에서 recall-precision 그래프에 대한 설명은 많이들 나와있다. 그러나 object-detection 과정에서 recall-precision 그래프를 어떻게 그리는지에 대해서는 자료를 찾기가 어려웠다.
몇 가지 자료를 찾아보고 구현하기 위해 고민해본 결과 아래와 같은 Procedure 를 생각할 수 있었다.
1) Threshold 를 0으로 정해놓고 detection 알고리즘을 모든 test image 에 돌려본다.
- 이 때 non-maximum-suppression 을 on 으로 설정하였다. 실제 Test Time 에서 객체를 검출할 떄 NMS 를 on 하고 operation 하기 때문에 이렇게 하는 것이 맞는 것 같다.
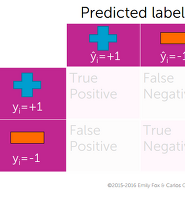
2) bounding-box 에 해당하는 confidence score (객체일 확률)과 true positive / false positive 여부를 Pair로 저장한다.
- bounding-box 좌표는 필요없다.
true positive / false positive 는 검출영역과 Ground-Truth 영역간의 겹치는 영역 (overlapped region) 으로 판단한다.
-
- if is true positive
- else is false positive
- : prediction box
- : ground truth box
3) (prob, ) pair 를 확률값에 따하 내림차순으로 정렬한다.
이렇게 하면 아래와 같은 recall-precision 그래프를 그릴 수 있다. 그래프 그리는 과정은 Evaluation 11: interpolated recall-precision plot 를 참조하자.

2.2. Interpolated recall-precision 값 11개를 구한다.
위 수식에 따라 11개의 recall 값에 대한 precision 값을 구한다.
- 11개의 recall 값 : [0.0, 0.1, …, 1.0] 의 evenly-spaced 11-values
2.3. AP 를 구한다.
이 과정은 간단하다. 11개의 precision 값을 평균낸다. 수식으로 표현하면 아래와 같다.
2.4. mAP 를 구한다.
여기도 간단하다. 1개 object 에 대한 측정값이 AP 이므로 여러개의 object 에 대해 AP 를 구하고 평균내면 mAP 가 된다.
3. Python Code
object-detector 프로젝트내에 mAP 값을 구하는 class 를 구현해 두었다. evaluate.py 를 참조하자.
4. 정리
- 장점 1: 인식 threshold 에 의존성없이 성능평가가 가능하다.
- 장점 2: mAP 평가를 통해 최적 threshold 를 정할 수 도 있다.
- 단점 : 굉장히 느리다. 아무래도 모든 Test Image 에서 Threshold 0 이상의 box 를 추출하고 정렬하는 과정을 거쳐야 하므로…
실제로 공부하고 구현해보면서 느낀 2가지 장점이다.
딥러닝을 이용한 object detection 논문중에 r-CNN 이라는 알고리즘을 개발한 것이 있다. region proposal 기술을 이용해 후보 영역을 뽑아내고 CNN 으로 가/부 를 결정하는 알고리즘인데, 그 논문을 보면서 문자인식에서도 비슷한 방법을 적용할 수 있지 않을까 생각했었던 적이 있다.
SWT (Stroke Width Transform) 과 같은 방법으로 문자의 후보영역을 추출하고 CNN 으로 더 정확한 인식을 하는 방법인데, 여기에 활용해보면 어떨까 싶다.
정확한 인식은 CNN 으로 할 것이므로 SWT 로는 precision 이 낮더라고 recall 1.0 이 되는 threshold 를 정하는 데에 활용가능할 것 같다.
'Machine Learning' 카테고리의 다른 글
| python 에서 RANSAC 으로 polynomial fitting 방법 (0) | 2017.09.16 |
|---|---|
| Likelihood, ML, MAP 개념 정리 (0) | 2017.08.16 |
| image morphological operations (0) | 2017.08.16 |
| Image Gradient (0) | 2017.08.16 |
| Precision / Recall (2) | 2017.08.16 |